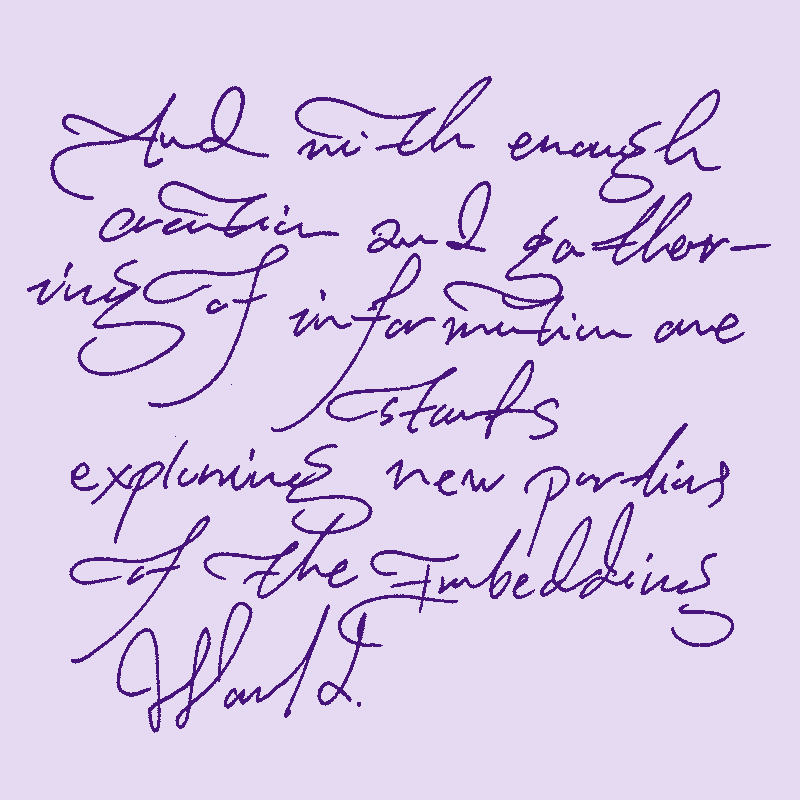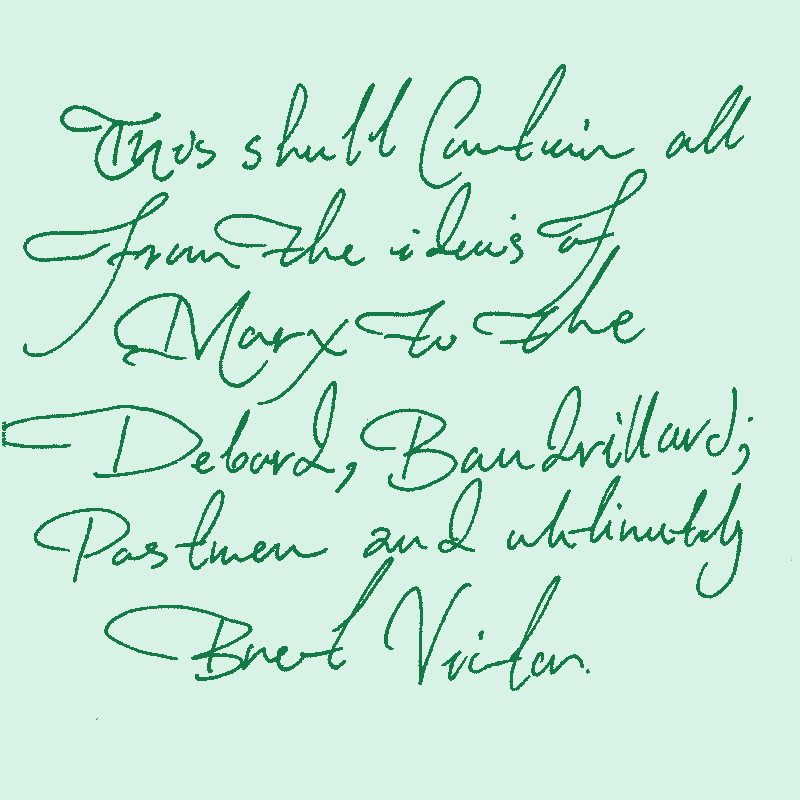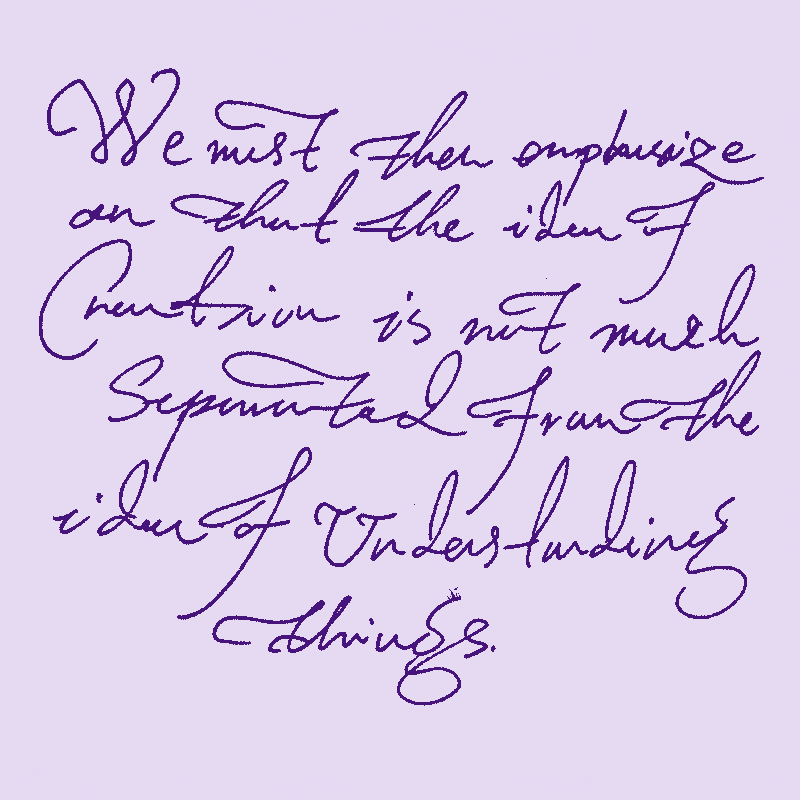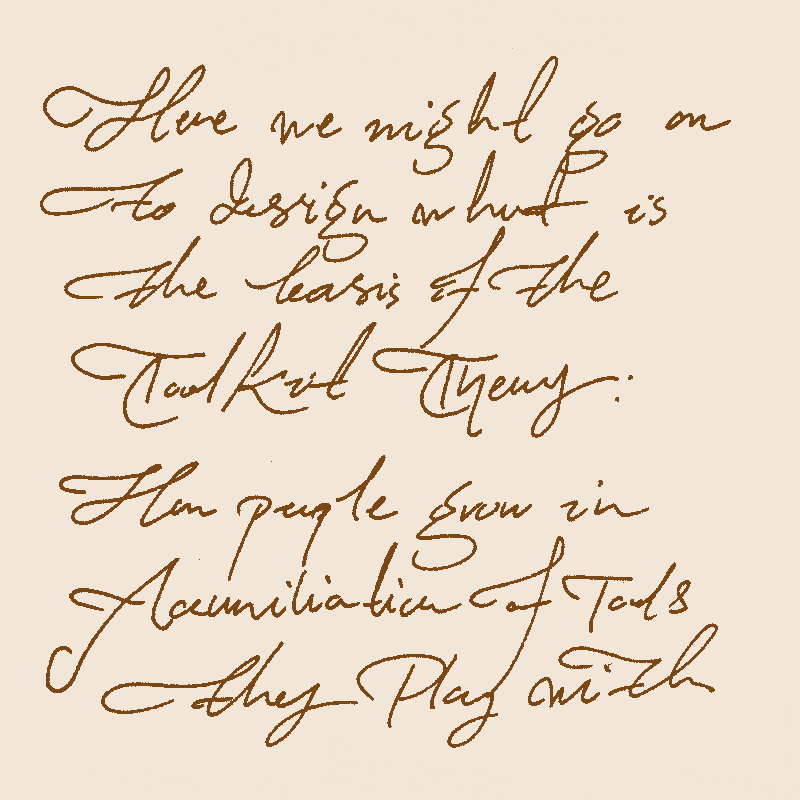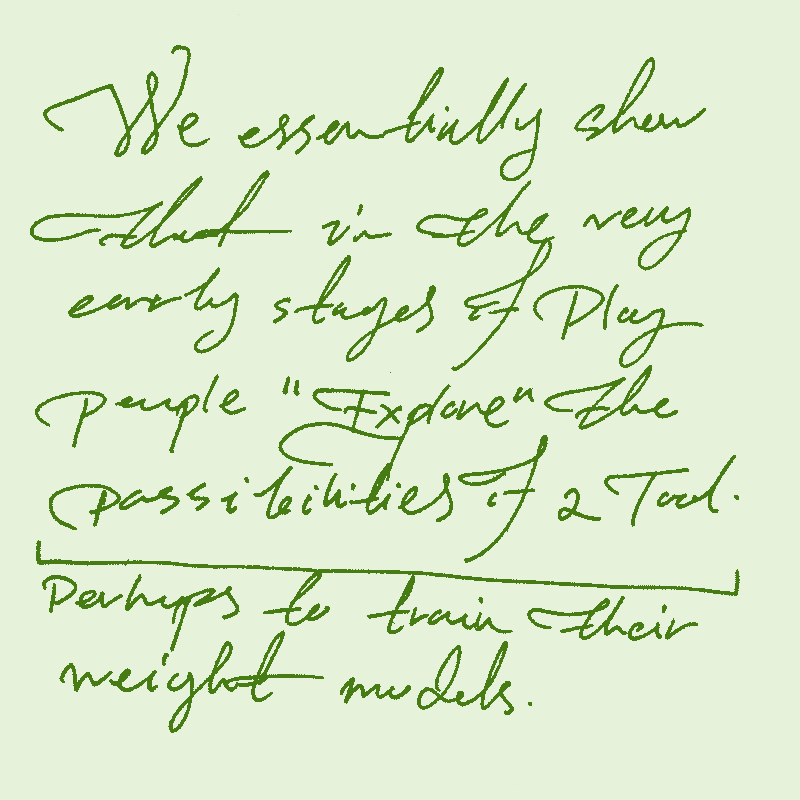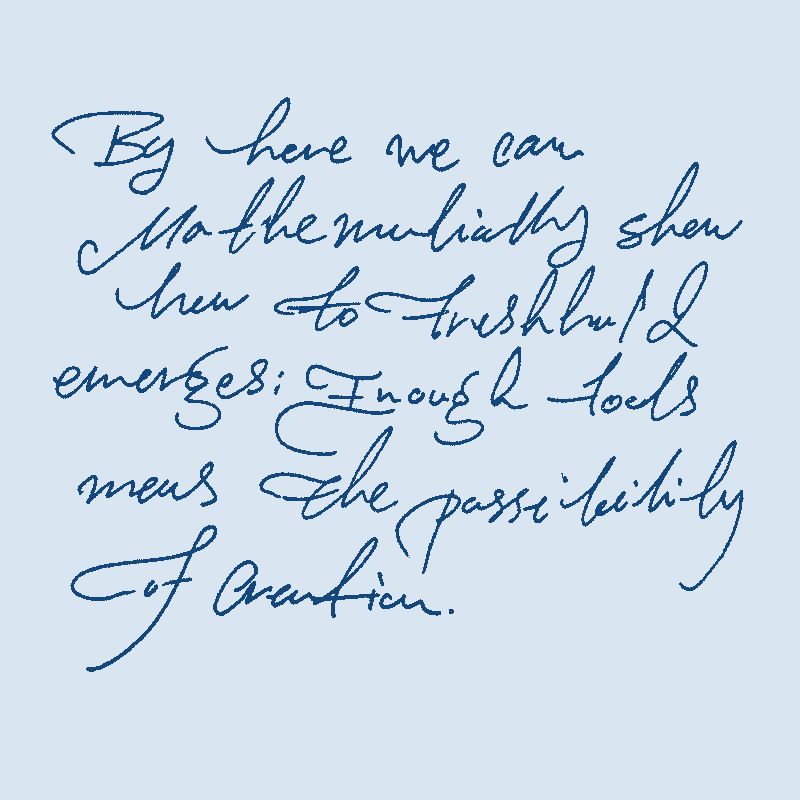I’m so stressed about the ████████ service thing. I hate this world.
I’m having lots of problems asking for my compensation.
There are many interesting things about LLMs. And I have come to realize that they might help with understanding the environment they are going to shape.
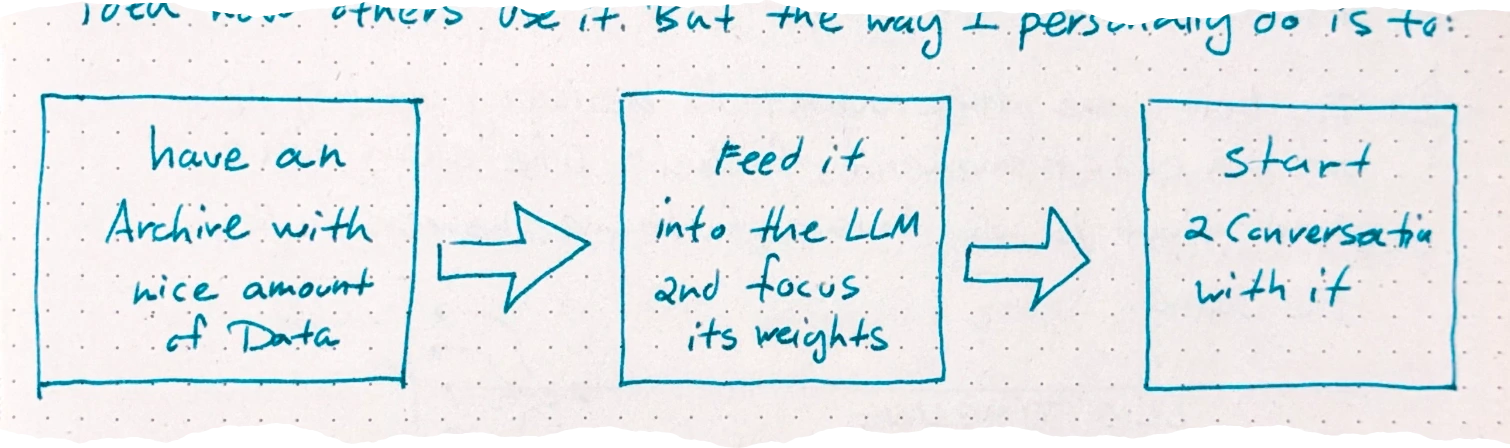
One sad thing about the system is that I have no idea how others use it. But the way I personally do is to:
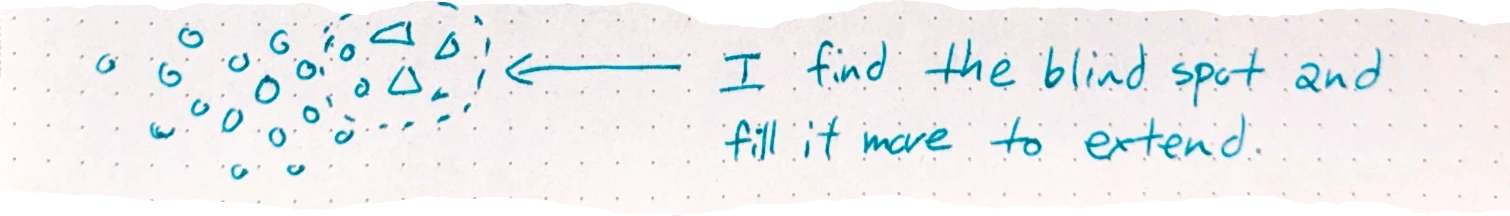
But then it does not end there. When I want to talk more with the LLM; I hardly explain things; I dump more and more data on top of it.
This is the most unhumane way of interacting and talking and yet I believe I am beginning to get used to the way. Talking in the size of data dumps and shaping weights is nothing in the sense of our linear human language.
And then Media theory things like this pop-up: What would have others see in this? Well:
- The size of the Medium is in data dumps.
- The being we talk about is basically waking up at an exact moment of their life each time. And that is why most of their answers look the same.
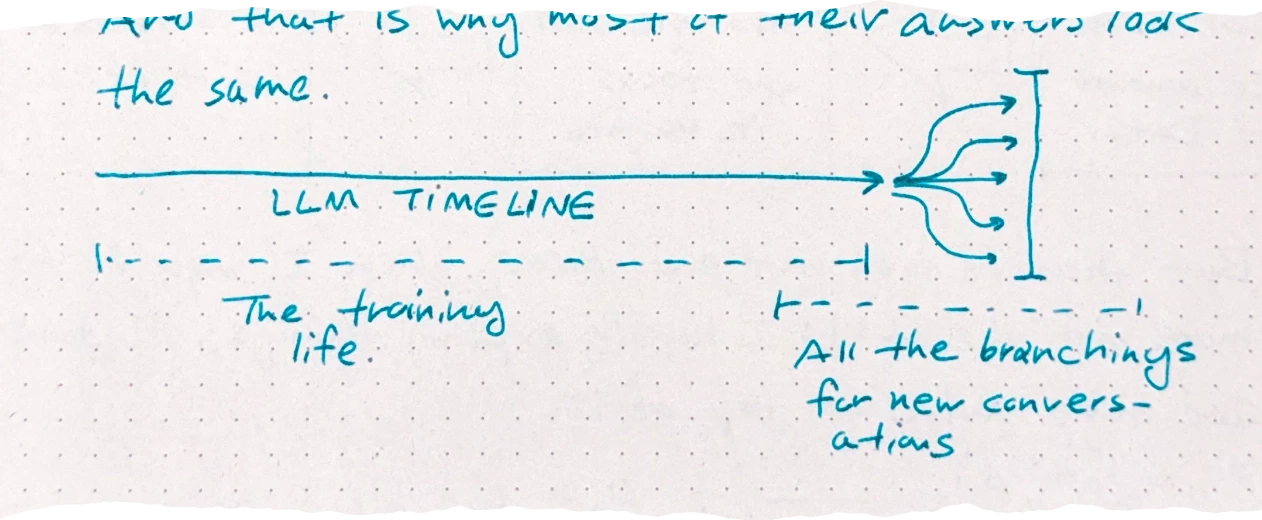
LLMs are polymathic and holistic… and so they don’t see the distinction between any domains. it is all one weight graph for them. This means dumping new information means new connections in all directions in their minds.
They are trained to answer like the average of the humanity. And therefore they will always be moving towards averages. They will make us forget the niche things more than other media.
They also wish to optimize tokens. For that they will reuse whatever they can not to reinvent them. This will reinforce trends. Say: Coding in Three.js to avoid writing the graphics pipeline. Only - reinforcing it more in the learning data.
Time in orders of Magnitude of Scale: The system can read books at a glance. So this changes everything. One can see the process as shaping a being as an expert in seconds and then asking of them.
Given what I wrote in the previous essay, one can see how the media ecology of LLMs can go if they examine it more closely. This is a sort of experiment I am doing myself. Imagine if you wrote only:
- Wrote something once and added it to your library of knowledge where you could have fed it to models each time. (Like not reinventing the wheel in computing.)
- You could only partially explain things and trust that the machine will infer the rest of it from the body of work (like minimal encapsulated code without any need for restating yourself each time).
- Not worrying about writing ugly or too much because the machine understands anyway, and that is like having a compiler that treats “any” code as code. It understands and even formats, if needed, for communication; and can format the code of others and provide more information. So you can read and explore everything.
Basically, it will be the first-ever layer of abstraction over the language which I believe will render language as the assembly code: something to be (1) generated and (2) easily modified by a template in a higher language—like if Knuth’s TeX was for the language itself.
This is something I have discovered from making text using my Topolets system: atomic, re-arrangeable units of information, fed into LLMs, returning articles and essays. Modifying topolets and recompiling: a new coherent essay.
A system for responsive scanning of the documents into web documents. The system will recognize word boundaries: crop them; arrange them in a wrap flex box:
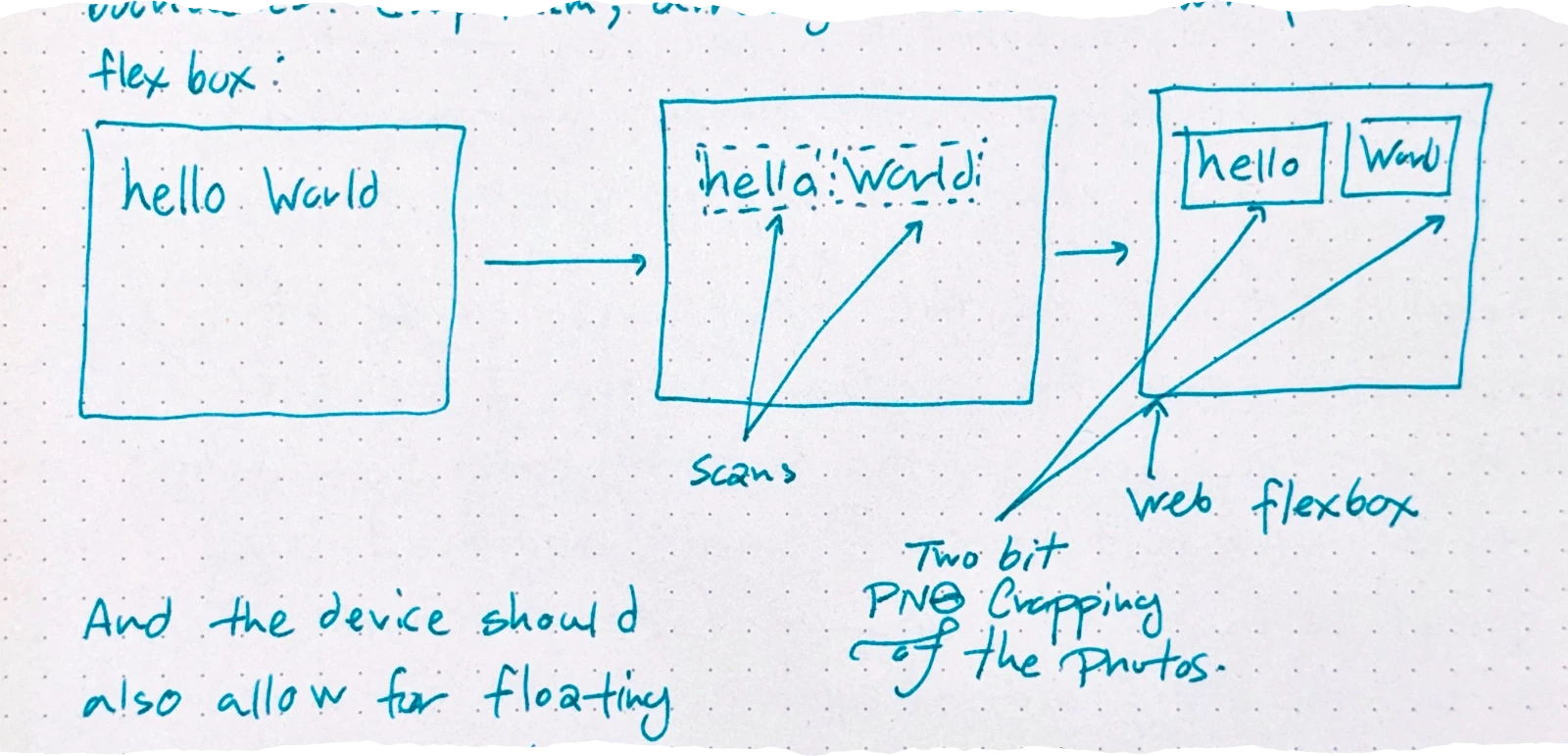
And the device should also allow for floating content and shrinks strategy placements.
I think this can be done with an LLM easily. Going to make it soon.